Top 10 des modèles de conception de microservices : expliqués dans un langage simple (avec des exemples réels)
Si vous créez, passez un entretien ou essayez simplement de comprendre des microservices, c’est la seule liste dont vous avez besoin.
Il y a quelques années, toutes les discussions sur l’architecture auxquelles j’ai assisté ont fini par aboutir sur la même ligne :
“Nous devrions diviser ce monolithe en microservices.”
Tout le monde hocha la tête. Personne n’a posé la question suivante :
« Quels modèles allons-nous utiliser pour que ces microservices fonctionnent réellement ensemble ? »
Cette deuxième question est celle qui décide si votre projet de microservices réussit ou se transforme en un désordre distribué plus difficile à gérer que le monolithe que vous venez de tuer.
Ainsi, dans cet article, je détaille les 10 principaux modèles de conception de microservices, non pas dans le langage des manuels, mais dans la manière dont je les explique à mes mentorés : simples, pratiques et liés aux situations réelles auxquelles vous serez réellement confrontés.
Allons-y.
1. Modèle de passerelle API
L’idée simple : Ne laissez pas les clients parler directement à 20 microservices différents. Donnez-leur une seule porte à laquelle frapper.
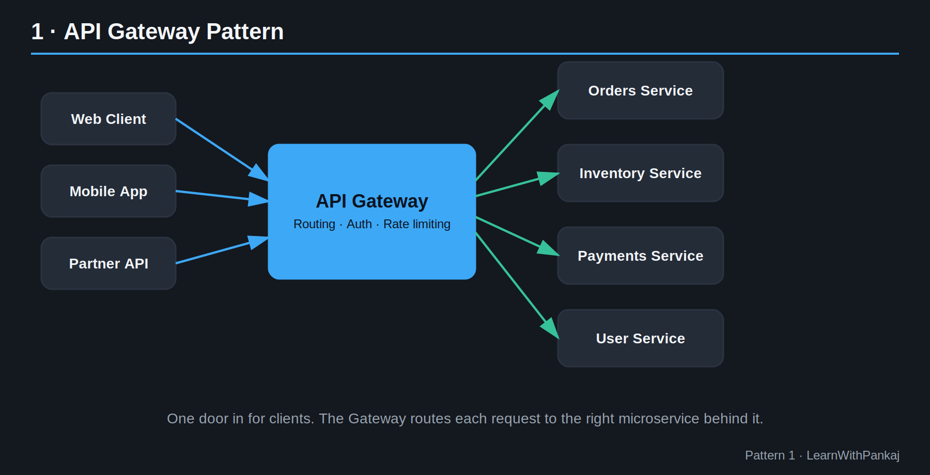
Imaginez un hôtel. Les clients ne se promènent pas directement dans la cuisine, la buanderie ou la salle de maintenance : ils se rendent à la réception, et la réception achemine la demande vers le bon service.
L’API Gateway est cette réception. Il s’intercale entre vos clients (web, mobile, applications tierces) et vos microservices, et gère :
• Acheminement des demandes vers le bon service
• Authentification et autorisation
• Limitation du débit
• Combiner les réponses de plusieurs services en un seul
Pourquoi c’est important : Sans cela, chaque client doit connaître l’adresse, les règles de sécurité et les bizarreries de chaque microservice. C’est un cauchemar de maintenance qui attend de se produire.
Outils populaires : Gestion des API Azure, AWS API Gateway, Ocelot (.NET), Kong, YARP.
2. Modèle de découverte de services
L’idée simple : Les services ont besoin d’un « répertoire » pour se retrouver, car leurs adresses changent tout le temps.
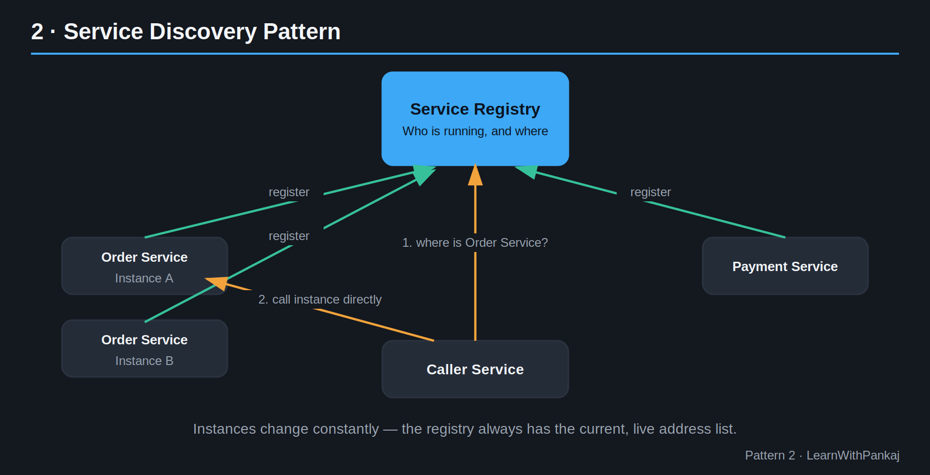
Dans un monolithe, une partie de votre code en appelle directement une autre. Dans les microservices, les instances démarrent, s’arrêtent, évoluent et diminuent constamment, en particulier dans le cloud ou Kubernetes. Le codage en dur des adresses IP ne fonctionne tout simplement pas.
Service Discovery conserve un registre en direct et mis à jour indiquant qui est en cours d’exécution et où :
• Découverte côté client : le service appelant interroge directement le registre, puis appelle le service cible.
• Découverte côté serveur : un équilibreur de charge ou une passerelle effectue la recherche en votre nom.
Outils populaires : Consul, Eureka, découverte des services intégrés de Kubernetes.
3. Modèle de disjoncteur
L’idée simple : Si un service continue de tomber en panne, arrêtez de le toucher pendant un moment, tout comme un disjoncteur électrique se déclenche pour éviter un incendie.
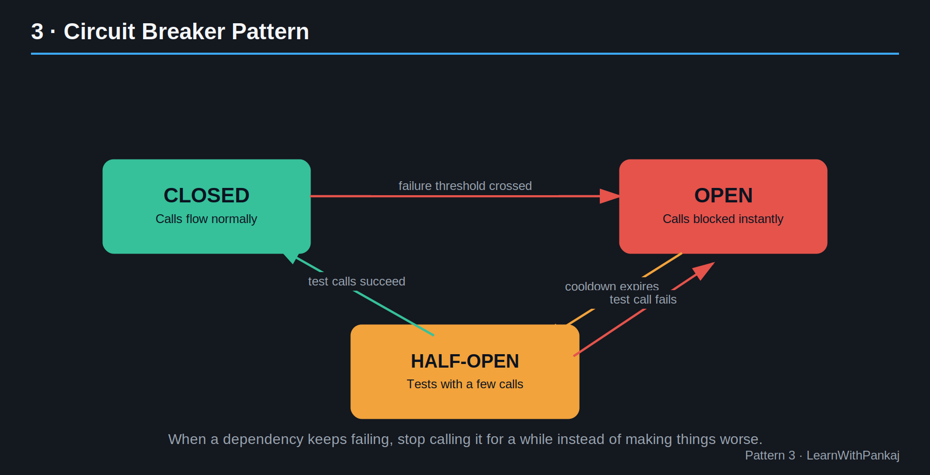
Imaginez ceci : le service A appelle le service B. Le service B est surchargé et commence à expirer. Si le service A continue de réessayer, il gaspille des ressources, ralentit et l’échec se propage comme un virus : c’est ce qu’on appelle un échec en cascade.
Un disjoncteur surveille le taux de défaillance. Une fois qu’il franchit un seuil, il « ouvre » le circuit et arrête d’appeler le service défaillant pendant une période de refroidissement, renvoyant à la place une réponse de repli. Après un certain temps, il teste à nouveau le terrain (état « semi-ouvert ») avant de faire à nouveau pleinement confiance au service.
Pourquoi c’est important : Il s’agit du modèle le plus important pour empêcher un service défaillant de détruire l’ensemble de votre système.
Outils populaires : Polly (.NET), Resilience4j (Java), Hystrix (hérité).
4. Modèle de saga
L’idée simple : Lorsqu’une transaction commerciale s’étend sur plusieurs services, vous ne pouvez pas utiliser une transaction de base de données traditionnelle : vous la divisez donc en une séquence d’étapes plus petites, chacune avec un plan « d’annulation ».
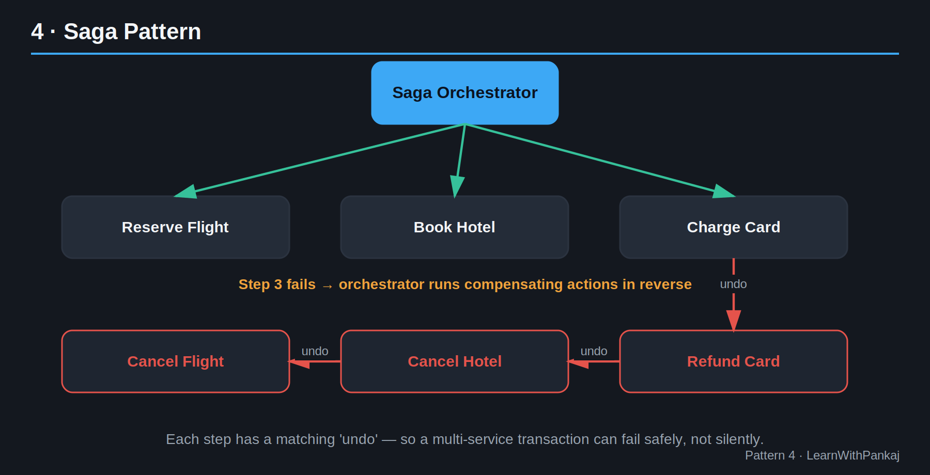
Imaginez réserver un voyage : vous réservez un vol, réservez un hôtel et débitez une carte de crédit – trois services différents. Que se passe-t-il si la réservation d’hôtel échoue alors que le vol est déjà réservé ?
Vous ne pouvez pas annuler comme une transaction SQL entre les services. Le modèle Saga résout ce problème avec deux approches :
• Chorégraphie: chaque service écoute les événements et réagit — pas de contrôleur central.
• Orchestration: un « orchestrateur de saga » central indique à chaque service quoi faire, étape par étape, et déclenche des actions compensatoires (comme l’annulation du vol) en cas d’échec.
Astuce bonus : Le modèle de boîte d’envoi est étroitement lié à Saga, qui garantit qu’un service met à jour sa base de données et publie un événement en une seule étape atomique, afin que vous ne perdiez jamais un événement en raison d’un crash entre les deux opérations.
Pourquoi c’est important : C’est ainsi que les transactions distribuées du monde réel (commandes, paiements, réservations) sont traitées sans verrouiller l’ensemble du système.
5. CQRS (ségrégation des responsabilités des requêtes de commande)
L’idée simple : Séparez la façon dont vous écrivez les données de la façon dont vous les lisez.
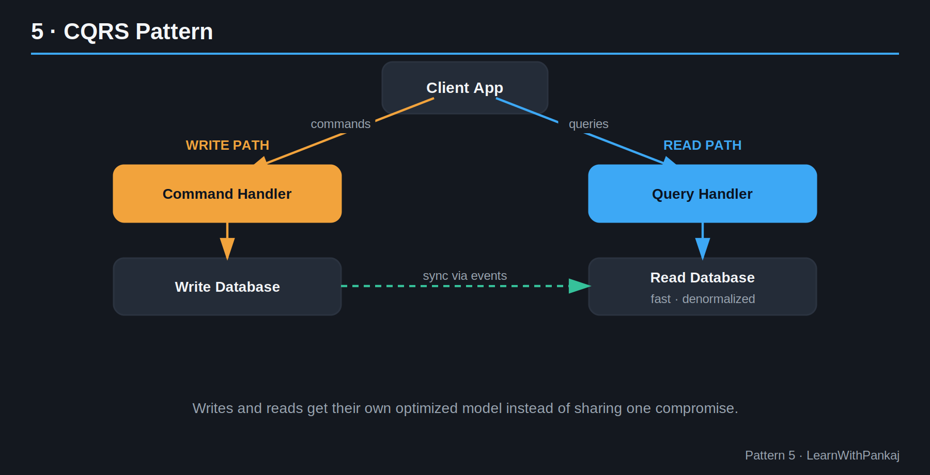
Dans la plupart des applications, un modèle gère à la fois les lectures et les écritures. Cela fonctionne bien jusqu’à ce que votre trafic de lecture et votre trafic d’écriture aient des besoins très différents : par exemple, un million de personnes consultent une page de produit, mais seulement quelques centaines passent des commandes.
CQRS divise cela en :
• Côté commande : gère les écritures (création, mise à jour, suppression) — optimisées pour la cohérence et les règles métier.
• Côté requête : gère les lectures – optimisées pour la vitesse, utilisant souvent un modèle de données dénormalisé ou mis en cache.
Prudence: N’utilisez pas CQRS partout. Cela ajoute une réelle complexité – gardez-le pour les services avec des demandes de lecture/écriture véritablement différentes.
Pourquoi c’est important : Vous pouvez adapter les lectures et les écritures indépendamment et concevoir chaque côté en fonction de ce pour quoi il est réellement bon.
6. Modèle de recherche d’événements
L’idée simple : Au lieu de stocker uniquement l’état actuel des données, stockez chaque changement (événement) qui leur est arrivé.
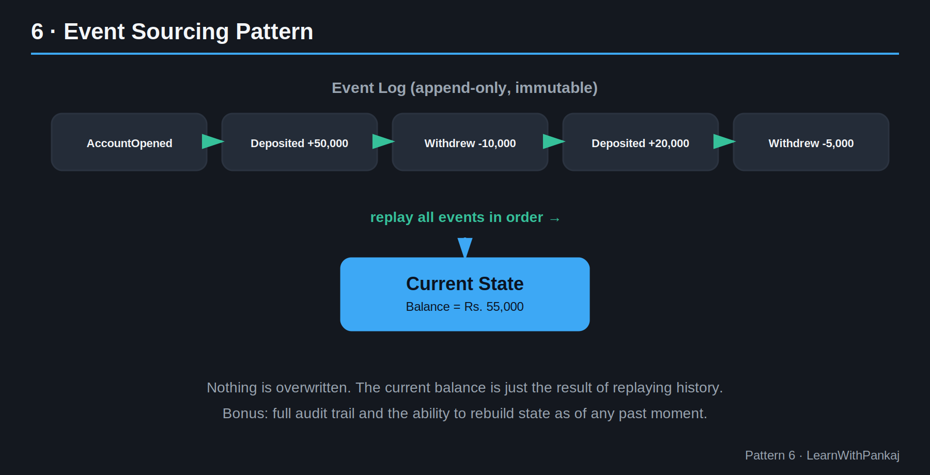
Pensez à votre compte bancaire. La banque ne stocke pas seulement le « solde : 50 000 ₹ ». Il stocke chaque dépôt et retrait – l’historique complet – et votre solde actuel est simplement le résultat de la relecture de tous ces événements.
C’est le sourcing d’événements. Chaque changement d’état est enregistré en tant qu’événement immuable et l’état actuel est reconstruit en relisant le journal des événements.
Pourquoi c’est important : Vous bénéficiez gratuitement d’une piste d’audit complète, de la possibilité de « voyager dans le temps » vers n’importe quel état passé et d’un débogage plus facile de « Comment les données se sont-elles retrouvées ainsi ? »
Outils populaires : Se marie bien avec CQRS et le modèle de boîte d’envoi.
7. Modèle de figue étrangleur
L’idée simple : Ne réécrivez pas votre monolithe dans une seule version big bang. Développez lentement de nouveaux microservices autour de lui jusqu’à ce que l’ancien monolithe disparaisse – comme un figuier étrangleur qui pousse autour d’un vieil arbre jusqu’à ce que l’original disparaisse.
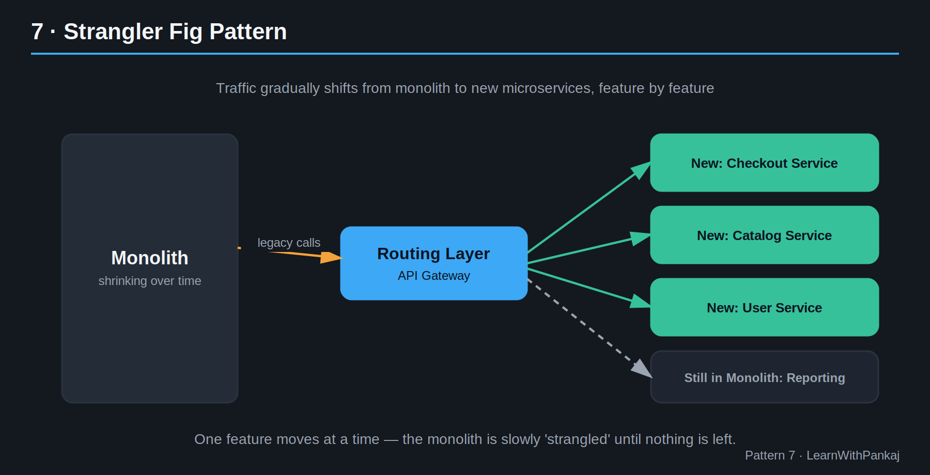
Concrètement, cela signifie :
• Placez une couche de routage (souvent la passerelle API) devant le monolithe.
• Créez un nouveau microservice pour une fonctionnalité spécifique.
• Acheminez uniquement le trafic de cette fonctionnalité vers le nouveau service.
• Répétez, fonctionnalité par fonctionnalité, jusqu’à ce que le monolithe ne fasse rien – et que vous l’éteigniez.
Pourquoi c’est important : Il s’agit du moyen le plus sûr et le moins risqué de migrer un système existant sans passer par un moment à enjeux élevés : « appuyez sur l’interrupteur et priez ».
8. Modèle side-car
L’idée simple : Attachez un composant d’assistance à côté de votre service pour gérer les éléments « non commerciaux », au lieu d’écrire cette logique dans chaque service.
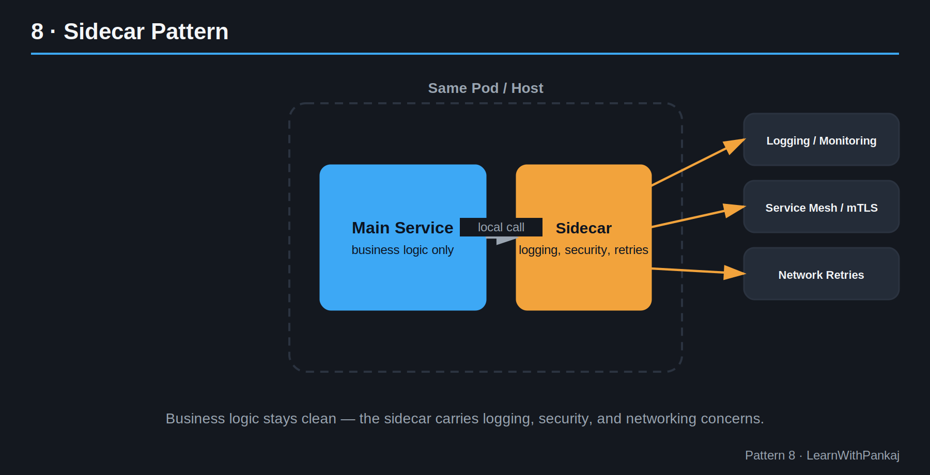
Un side-car s’exécute à côté de votre service principal (souvent dans le même pod, en termes Kubernetes) et gère des choses comme :
• Journalisation et surveillance
• Sécurité de service à service (mTLS)
• Nouvelles tentatives de réseau et coupure de circuit
Considérez-le comme un side-car de moto : il voyage avec le véhicule principal mais transporte sa propre cargaison séparée.
Pourquoi c’est important : Votre logique métier reste propre. Les préoccupations transversales (journalisation, sécurité, mise en réseau) résident dans le side-car, et non dispersées dans la base de code de chaque service.
Outils populaires : Istio, Linkerd (implémentations de maillage de services utilisant des side-cars).
9. Modèle de cloison
L’idée simple : Isolez les ressources afin qu’une partie surchargée de votre système ne puisse pas couler tout le navire.
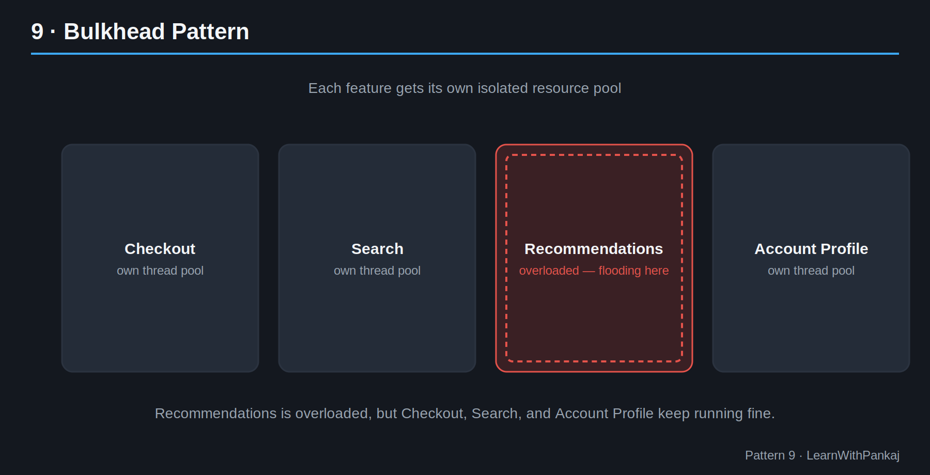
Le nom vient directement de la construction navale : les navires sont divisés en compartiments étanches (cloisons) de sorte que si une section est inondée, le reste du navire reste à flot.
Dans les microservices, cela signifie :
• Donner à différents services leurs propres pools de threads, pools de connexions ou limites de ressources.
• S’assurer qu’une dépendance lente ou défaillante pour une fonctionnalité n’épuise pas les ressources nécessaires à une fonctionnalité critique.
Pourquoi c’est important : Il contient l’échec dans un petit rayon d’explosion au lieu de le laisser tout détruire. Souvent associés à un disjoncteur, ils rendent votre système véritablement tolérant aux pannes.
10. Base de données par modèle de service
L’idée simple : Chaque microservice possède sa propre base de données : aucun service ne doit accéder directement à la base de données d’un autre service.

C’est le modèle qui rend tout le reste de cette liste nécessaire en premier lieu. Si chaque service pouvait simplement interroger directement la base de données de tous les autres services, vous n’auriez pas besoin d’une passerelle API, d’une saga ou d’un CQRS – et vous seriez également de retour à un monolithe étroitement couplé, simplement divisé en plusieurs bases de code.
Avec base de données par service :
• Chaque équipe peut choisir la technologie de base de données adaptée à son service (SQL, NoSQL, etc.).
• Les services peuvent être déployés et mis à l’échelle indépendamment.
• Un changement de schéma dans un service n’en interrompt pas cinq autres.
Le compromis : Vous perdez des jointures interservices faciles et des transactions ACID – c’est exactement pourquoi des modèles comme Saga et CQRS existent.
Pourquoi c’est important : C’est le fondement. Si vous vous trompez, tous les autres modèles de cette liste deviennent plus difficiles à appliquer correctement.
Rassembler tout cela
Voici comment ces modèles apparaissent généralement ensemble dans un système réel :
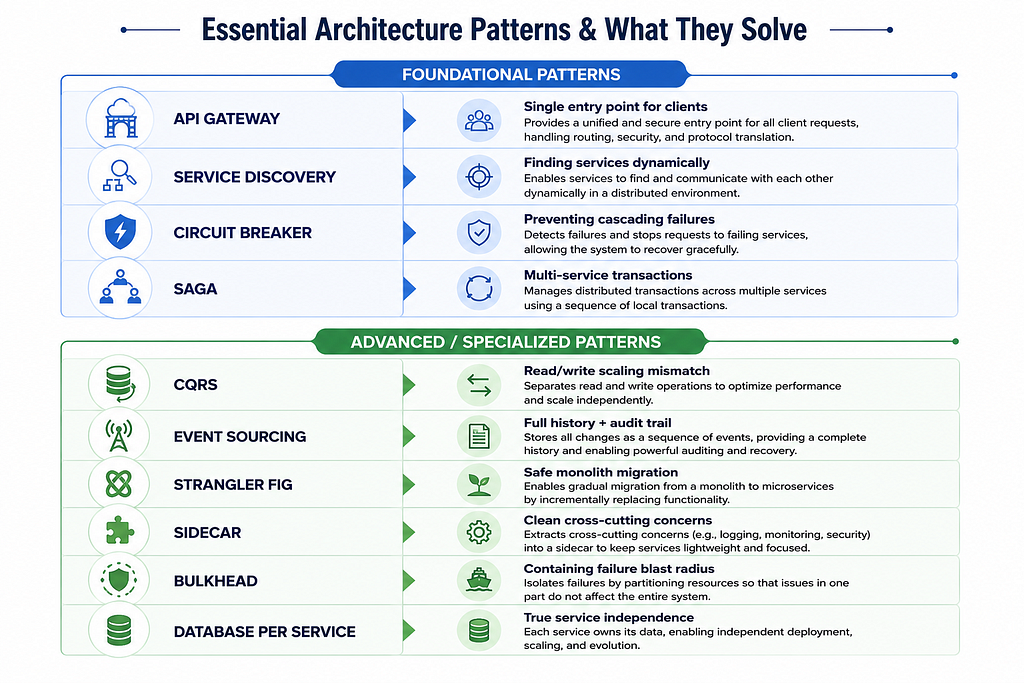
Vous n’avez pas besoin des dix dès le premier jour. La plupart des équipes commencent par Base de données par service + Passerelle API + Disjoncteur, et ajoutent le reste lorsque de vrais problèmes apparaissent : Saga lorsque les transactions s’étendent sur les services, CQRS lorsque les charges de lecture/écriture divergent, Event Sourcing lorsque l’historique d’audit devient critique.
Pensée finale
Les microservices n’échouent pas parce que l’idée est fausse. Ils échouent parce que les équipes adoptent l’architecture sans adopter les modèles qui la rendent gérable.
Si vous vous préparez à un entretien de conception de système, ou si vous construisez un système de microservices au travail, connaissez ces dix principes – pas seulement les définitions, mais le véritable problème que chacun résout. C’est ce qui différencie quelqu’un qui a mémorisé des mots à la mode de quelqu’un qui peut réellement concevoir un système qui survit au trafic de production.
Si cela vous a aidé à clarifier l’architecture des microservices, suivez la suite pour une analyse plus approfondie de .NET, Azure et de la conception de systèmes, écrite pour les développeurs du monde réel, et pas seulement pour les réponses aux examens.
Les 10 meilleurs modèles de conception de microservices : expliqués dans un langage simple (avec des exemples réels) ont été initialement publiés dans Stackademic sur Medium, où les gens poursuivent la conversation en soulignant et en répondant à cette histoire.
PakarPBN
A Private Blog Network (PBN) is a collection of websites that are controlled by a single individual or organization and used primarily to build backlinks to a “money site” in order to influence its ranking in search engines such as Google. The core idea behind a PBN is based on the importance of backlinks in Google’s ranking algorithm. Since Google views backlinks as signals of authority and trust, some website owners attempt to artificially create these signals through a controlled network of sites.
In a typical PBN setup, the owner acquires expired or aged domains that already have existing authority, backlinks, and history. These domains are rebuilt with new content and hosted separately, often using different IP addresses, hosting providers, themes, and ownership details to make them appear unrelated. Within the content published on these sites, links are strategically placed that point to the main website the owner wants to rank higher. By doing this, the owner attempts to pass link equity (also known as “link juice”) from the PBN sites to the target website.
The purpose of a PBN is to give the impression that the target website is naturally earning links from multiple independent sources. If done effectively, this can temporarily improve keyword rankings, increase organic visibility, and drive more traffic from search results.